
Una de las herramientas que estoy usando en modo local de IAG, es Ollama que está teniendo un desarrollo muy importante.
¿Qué es Ollama?
OLLAMA (Open-source Library for AI Models and Applications) es una herramienta de código abierto (Open Source) que permite a modo de plataforma ejecutar una amplia variedad de modelos de lenguaje LLM en nuestros ordenadores de manera offline, es decir, en modo local sin necesidad de conectarnos a internet para poder usar los LLMs.
Es compatible con los principales sistemas operativos como macOS, Linux y Windows.
Instalación de Ollama paso a paso
Para poder usar Ollama tenemos dos tres métodos:
1.- Descargándolo de la web https://ollama.com y usando el interfaz de la línea de comandos (CLI)
2.- Utilizando Docker, que es el que recomendamos.
3.- ¿Brew? https://formulae.brew.sh/formula/ollama (No lo hemos probado, al opinar que es distinto pero similar a Docker pero más fácil con Docker).
😉Estamos abierto a otras sugerencias, método o preferencias. Mándanos un mail.
Como decíamos, antes de empezar a instalar Ollama desde su propia página web, os recomendamos su uso desde Docker.
Cierto que el uso de Ollama desde el CLI puede ser muy fácil y nos da opciones de parametrización o de definir el uso de Ollama con los comandos que trae, pero al final estaremos trabajando sin un entorno gráfico que es mucho más cómodo y similar al uso de otros Chats como el de OpenAI.
¿Qué es Docker?
Según la Wikipedia, Docker es un proyecto de código abierto que automatiza el despliegue de aplicaciones dentro de contenedores de software, proporcionando una capa adicional de abstracción y automatización de virtualización de aplicaciones en múltiples sistemas operativos.
Los contenedores son paquetes de software que incluyen todos los elementos necesarios para ejecutar tus productos en cualquier entorno. Como virtualizan el sistema operativo, se pueden ejecutar en cualquier parte, desde un centro de datos privado hasta la nube pública o incluso el portátil personal.
https://hub.docker.com/r/ollama/ollama
Instalación de Ollama desde Docker
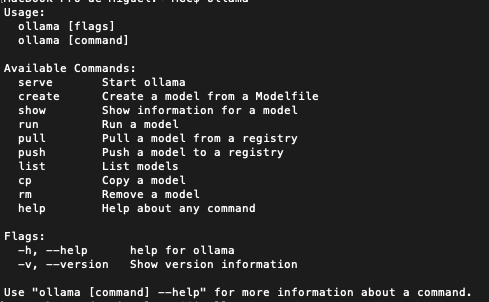
Si queremos instalar Ollama en un ordenador que no tiene GPU – es decir, que solo tenemos CPU – procederemos a ejecutar en el CLI la siguiente orden:
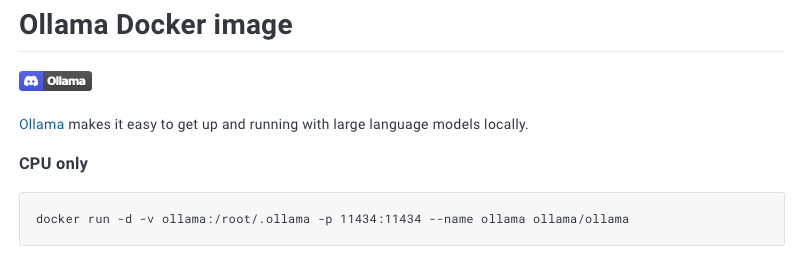
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaEn otra documentación de OpenWebUI se indica que se debe ejecutar ésta orden en el CLI:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaNosotros con la primera nos funcionó.
Si queremos instalarlo para sacarle rendimiento a la GPU, deberemos seguir las instrucciones que vienen detalladas en : https://hub.docker.com/r/ollama/ollama
Open WebUI
Open WebUI es una WebUI (interface de web) autohospedada extensible, rica en funciones y fácil de usar, diseñada para funcionar completamente sin conexión a internet.
Para ejecutar Ollama, hecho todos éstos pasos anteriores, o bien vamos a la siguiente dirección en el navegador: http://localhost:3000 o clickamos en el Docker en la opción open-webui (hacen lo mismo).
Podemos ver el entorno de trabajo de Ollama, similar como decíamos al de OpenAI.
Tenemos que tener en cuenta, que para hacer funcionar un modelo LLM tipo 7B, necesitamos que nuestro ordenador tenga al menos 8Gb de RAM.
Si el modelo es del tipo 13B deberemos tener 16Gb y si es de 33B deberemos tener 32Gb de RAM para que funcione con cierta fluidez.
Cuánto más grandes sea un modelo, más espacio en disco duro deberemos tener ya que como podéis ver en la tabla, hay modelos de muchos Gb, como por ejemplo Command R+ 104B que ocupa 60Gb.
Teniendo claro la limitación que pueda tener nuestro ordenador, lo primero que deberemos hacer, es seleccionar el modelo que queremos usar.
Web UI de Ollama
El diseño web UI, es aquel que organiza todo lo que sucede en la pantalla de un dispositivo, para que se dé la interacción entre el humano y la máquina. Nace de las siglas UI (User Interface).
Si todo ha salido bien, tendremos que ver ésta pantalla. Arriba te da la opción de seleccionar un modelo de LLM en concreto.
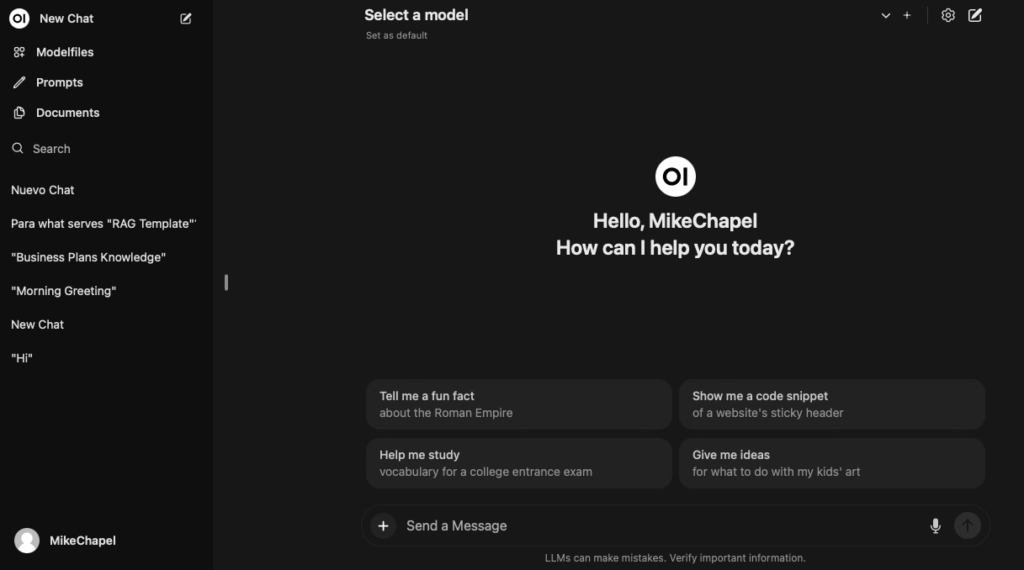
Hay una lista amplia en Ollama que puedes ver aquí: https://ollama.com/library
Tabla de modelos LLM para Ollama
Para facilitar la selección os adjuntamos una tabla con algunos de los más populares LLM. Tendréis qu hacer en cierta manera ensayo-error para encontrar el modelo que mejor se ajuste.
También os recomiendo la lectura de la entrada «EJECUTAR MODELOS LLM EN LOCAL SIN GPU – COMPARATIVA PRÁCTICA DE MODELOS» de la web AGENTES DE LA IA que analiza diferentes modelos: https://www.agentesdeia.com/ejecutar-modelos-llm-local/
| Nombre Modelo | Tamaño | Casos de uso principal |
|---|---|---|
| Llama 2 7b | 3.8GB | Trained on 2 trillion tokens, and by default supports a context length of 4096. Llama 2 Chat models are fine-tuned on over 1 million human annotations, and are made for chat. |
| Llama 3 8b | 4.7GB | Llama 3 instruction-tuned models are fine-tuned and optimized for dialogue/chat use cases and outperform many of the available open-source chat models on common benchmarks. |
| Phi-3 Mini 3.8B | 2.3GB | Entrenado por Microsoft centrado en el sentido común, la comprensión del lenguaje, las matemáticas, el código, el contexto largo y el razonamiento lógico. |
| WizardLM 2 7b | 4.1GB | Modelo de lenguaje grande de última generación de Microsoft AI con un rendimiento mejorado en casos de uso complejos de chat, multilingüe, razonamiento y agente. |
| Mistral 7B | 4.1GB | El modelo 7B lanzado por Mistral AI, actualizado a la versión 0.2. (23/03/2024) |
| Gemma 9B | 5.0GB | Nuevo modelo abierto desarrollado por Google y su equipo de DeepMind. Está inspirado en los modelos de Gemini en Google. |
| Mixtral | 26GB | Está entrenado en inglés, francés, italiano, alemán y español con fuertes capacidades de matemáticas y codificación y una ventana de contexto de 64K tokens permite la recuperación precisa de información de documentos grandes. |
| CodeGemma 9B | 5,0 GB | Puede realizar una variedad de tareas de codificación, como completar el código, generación de código, comprensión del lenguaje natural, el razonamiento matemático y el seguimiento de instrucciones. |
| Command R 35B | 20 GB | Optimizado para la interacción conversacional y las tareas de contexto largo, generación aumentada por recuperación (RAG) y el uso de API y herramientas externas, ideal para empresas. Contexto de 128k. |
| Command R+ 104B | 59GB | Similar al anterior pero instruido con mucho más volumen de datos, con ventana de contexto de 128k-token, Generación Aumentada de Recuperación Avanzada (RAG) con cita para reducir las alucinaciones. |
| LLaVA 7b | 4,7 GB | Modelo que combina un codificador de visión y Vicuna para la comprensión visual y del lenguaje de propósito general. Aumentar la resolución de la imagen de entrada hasta 4 veces más píxeles, soportando resoluciones de 672×672, 336×1344, 1344×336. Mejor razonamiento visual y capacidad de OCR con una mezcla de datos de ajuste de instrucciones visuales mejorada. |
| DBRX 132B | 74 GB | Preentrenado con tokens de 12T de datos de texto y código. Supera a modelos especializados como CodeLLaMA-70B en programación. Potente LLM de propósito general. |
| CodeLlama 7b | 3,8 GB | Modelo para generar y discutir código, construido sobre Llama 2: Python, C++, Java, PHP, Typescript (Javascript), C#, Bash y más. |
| Qwen 4b | 2.3GB | Modelo preentrenado en más de 2,2 billones de tokens, incluidos el chino, el inglés, los textos multilingües, el código y las matemáticas, que cubre campos generales y profesionales. |
| Mistral OpenOrca 7b | 4.1GB | Ajustado sobre el modelo Mistral 7B utilizando el conjunto de datos OpenOrca. |
| Dolphin-Mistral 7B | 4.1GB | Lanzada en marzo de 2024. Este modelo no tiene censura, está disponible tanto para uso comercial como no comercial, y sobresale en la codificación. |
| Phi 3B | 1,6 GB | El modelo de menor tamaño. Capaz de razonamiento de sentido común y comprensión del lenguaje |
| orca-mini | 2.0GB | Es un modelo de Llama entrenado en conjuntos de datos de estilo Orca. Tiene una amplia gama de aplicaciones y casos de uso potenciales, desde la generación de respuestas a preguntas específicas, hasta el desarrollo de diálogos interactivos. Facilidad de uso en entornos Jupyter Notebook y Uber GPT Web UI. |
| Open Hermes 7b | 4.1GB | Tiene fuertes habilidades de chat de varios turnos y capacidades de solicitud del sistema. En total, el modelo fue entrenado con 900.000 instrucciones, y supera todas las versiones anteriores de Nous-Hermes 13B e inferiores. |
| Vicuna 7b | 3.8GB | Vicuna es una modelo de asistente de chat. |
| Open Chat 7b | 4.1GB | Modelos de lenguaje de código abierto, afinado con C-RLFT: una estrategia inspirada en el aprendizaje de refuerzo fuera de línea. Supera a muchos otros modelos tipo 7b la versión última 1210. |
| TinyLlama 1b | 638MB | El modelo más pequeño. Idóneo para cuando no se dispone de memoria RAM, como por ejemplo traducción automática en tiempo real sin conexión a Internet. Este proyecto todavía está en desarrollo activo. |
Lo cierto, es que hay que ir probando qué modelo se ajusta mejor a nuestro HW y a nuestras necesidades.
¿Qué modelo has probado y cual es tu experiencia? Puedes compartirlo por Twitter a @aplicaia (no nos acostumbramos a llamarle X).
Otras fuentes:
- Ollama Tutorial: Running LLMs Locally Made Super Simple https://www.kdnuggets.com/ollama-tutorial-running-llms-locally-made-super-simple
- Run LLMs Locally using Ollama https://marccodess.medium.com/run-llms-locally-using-ollama-8f04dd9b14f9
- Cómo utilizar Ollama: práctica con LLM locales y creación de un chatbot https://hackernoon.com/es/como-usar-ollama-practicamente-con-llms-locales-y-construir-un-chatbot
- GitHub / Ollama https://github.com/ollama/ollama?tab=readme-ov-file
Comments are closed